Machine Learning
NeurIPS
Attention Is All You Need
Read on March 15, 2024
Published 2017
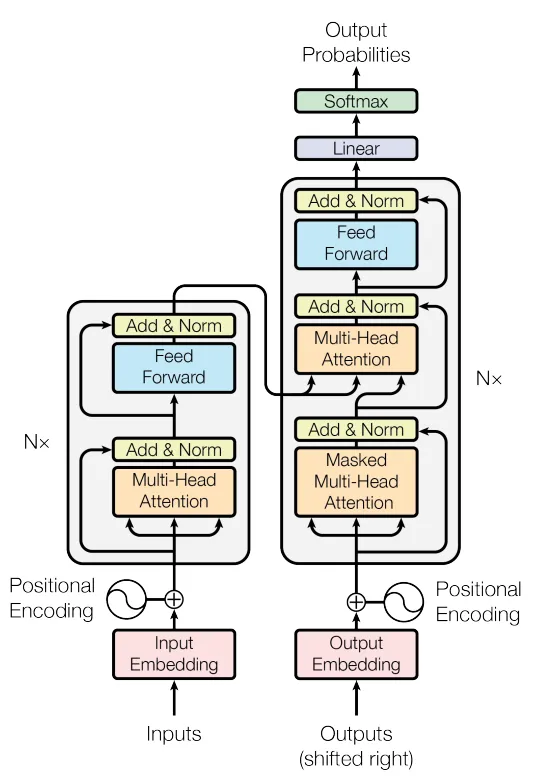
The 2017 paper Attention Is All You Need by Vaswani et al. introduced the Transformer architecture, revolutionizing the field of natural language processing (NLP) and beyond. This paper proposed a new way to handle sequence-to-sequence tasks without relying on traditional recurrent or convolutional networks, instead utilizing a mechanism called self-attention. The central idea of the Transformer is to allow the model to weigh the importance of different parts of the input sequence when producing outputs. By doing so, it overcomes the limitations of recurrent networks, such as sequential dependencies and vanishing gradients, offering a more efficient and scalable approach. The self-attention mechanism computes attention scores for every pair of words in the input sequence, enabling the model to capture long-range dependencies and contextual relationships more effectively. This approach is implemented through multi-head attention, where multiple attention mechanisms operate in parallel, capturing diverse aspects of the input data. Combined with positional encoding to retain order information, the Transformer achieves unparalleled performance in capturing linguistic nuances. Another key innovation in the paper is the encoder-decoder structure, where the encoder processes the input sequence and generates a contextual representation, while the decoder uses this representation to produce the output sequence, often word by word. This design facilitates efficient parallelization, making training faster compared to recurrent architectures. Furthermore, the introduction of scaled dot-product attention and layer normalization improved the stability and performance of the model. The paper also proposed techniques like residual connections and feedforward layers to enhance learning capabilities. The Transformer was evaluated on machine translation tasks, achieving state-of-the-art results on benchmarks like WMT 2014 English-to-German and English-to-French datasets. It outperformed existing models like recurrent neural networks (RNNs) and long short-term memory (LSTM) networks while requiring less computational time due to its parallelizable architecture. Its impact has been profound, with the model becoming the foundation for subsequent breakthroughs, including BERT, GPT, and many other NLP advancements. These models have been applied to a wide range of tasks, such as sentiment analysis, summarization, and question answering, demonstrating the Transformer’s versatility. The paper’s influence extends beyond NLP, as the architecture has been adapted for image processing, speech recognition, and even protein structure prediction. Reflecting on its significance, Attention Is All You Need not only introduced a powerful tool for machine learning but also reshaped our understanding of how attention mechanisms can serve as a universal framework for learning complex relationships in data. Its emphasis on scalability, efficiency, and performance has made it a cornerstone in the evolution of AI, inspiring countless research directions and practical applications.
Paper Information
Authors
Keywords
Attention Mechanism
Neural Networks
NLP
Sequence Modeling