Natural Language Processing
NAACL
BERT: Pre-training of Deep Bidirectional Transformers
Read on January 10, 2024
Published 2018
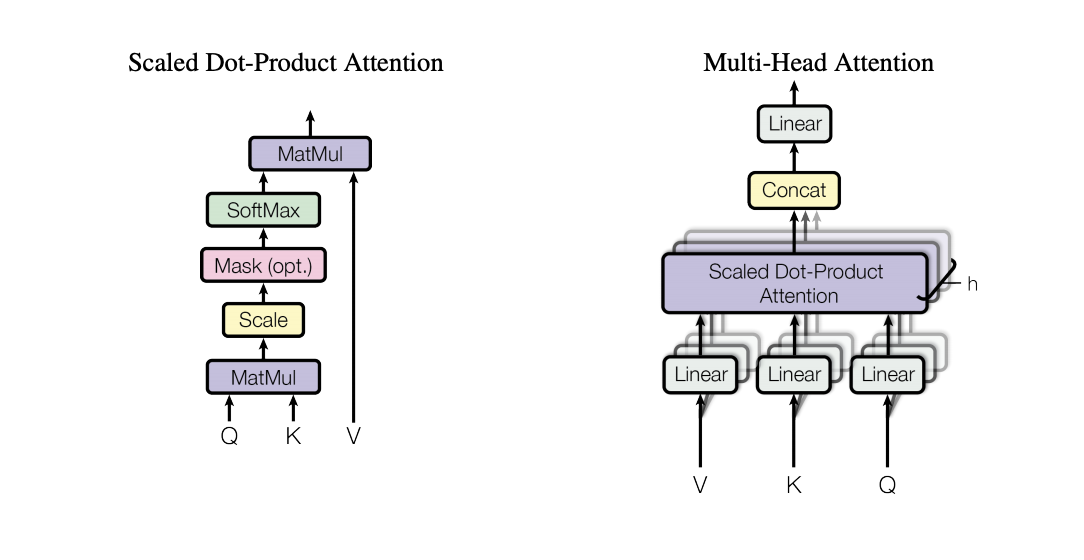
The paper BERT: Pre-training of Deep Bidirectional Transformers, introduced by Jacob Devlin and colleagues in 2018, revolutionized natural language processing (NLP) by presenting a new approach to pre-training language models. BERT, short for Bidirectional Encoder Representations from Transformers, is built on the Transformer architecture, enabling it to capture context from both directions—left-to-right and right-to-left—unlike earlier models that processed text unidirectionally. This bidirectional context understanding allowed BERT to generate more nuanced representations of words and sentences, improving performance across a wide range of NLP tasks. The pre-training process employed two novel objectives: masked language modeling (MLM), where random words in a sentence are masked, and the model learns to predict them based on context, and next sentence prediction (NSP), which trains the model to understand relationships between sentence pairs. These objectives helped BERT grasp both word-level and sentence-level semantics, making it highly effective in understanding complex language structures. BERT’s pre-training was conducted on vast corpora, including Wikipedia and BooksCorpus, resulting in a deeply rich linguistic understanding that could be fine-tuned for specific downstream tasks such as question answering, sentiment analysis, and named entity recognition. The model demonstrated state-of-the-art performance across multiple benchmarks, including the General Language Understanding Evaluation (GLUE) tasks and the Stanford Question Answering Dataset (SQuAD), setting a new standard in the field. Its pre-trained representations allowed researchers and practitioners to achieve impressive results with minimal task-specific training, greatly reducing the computational cost and data requirements for developing NLP models. BERT’s release also marked a significant shift toward transfer learning in NLP, inspiring a wave of subsequent models like RoBERTa, DistilBERT, and ALBERT, which further refined and extended its concepts. Today, BERT remains a cornerstone in NLP, powering applications ranging from search engines to virtual assistants, and its introduction is widely regarded as a pivotal moment in the evolution of AI.
Paper Information
Authors